
A few times a year, the Guardian’s Digital Development department organises a so-called ‘hack day’. These events, which actually take place over two days, are a great chance to get out of the office, try new technologies and hack on fun stuff. We also invite our colleagues from outside the department to join us, so it’s an opportunity to increase our interaction with journalists and other interesting Guardian people.
This year’s summer hack day was held at the beautiful Shoreditch Town Hall and caffeinated by Noble Espresso. The first morning was dedicated to generating ideas, then we hacked through the afternoon and the next morning. Finally each team presented their hack, people voted on their favourites, and we had a party to celebrate some great hacks.
Our hack was an experiment in helping our discussion moderators to find content that is likely to attract abusive or offensive comments. We receive tens of thousands of comments on the site every day, and our dedicated team of moderators works around the clock to find and remove any comments that do not meet our community standards. With so much new content being published every day, and an ever-increasing volume of comments, we wanted to help the moderators get on top of this workload and find the needles in the haystack.
Our hypothesis was that the number of problematic comments on an article follows a pattern, i.e. it can be predicted using attributes such as the words in the article’s headline, the section of the site in which the article is found, the tags describing the article, and so on. We decided to try using Amazon Machine Learning (AML) to train a model and perform predictions using regression analysis.
As the feature to predict, we invented a metric that we called the “removed ratio”, i.e. the number of comments removed by moderators divided by the total number of comments on the article. Our thinking was that a discussion with a lot of comments that need to be removed is one that should be watched by moderators. We calculated the removed ratio for about 200,000 existing discussions, queried the Content API for some extra fields that we hypothesised to be relevant, and uploaded it all as a CSV file to AML. From there it was relatively simple to follow Amazon’s wizard to build, train and evaluate a model.
When you import your CSV file into AML, a wizard guides you through the process of defining the schema, which basically involves specifying the data type of each field. It’s a good idea to include a header row in your CSV file so AML can give the fields sensible names.
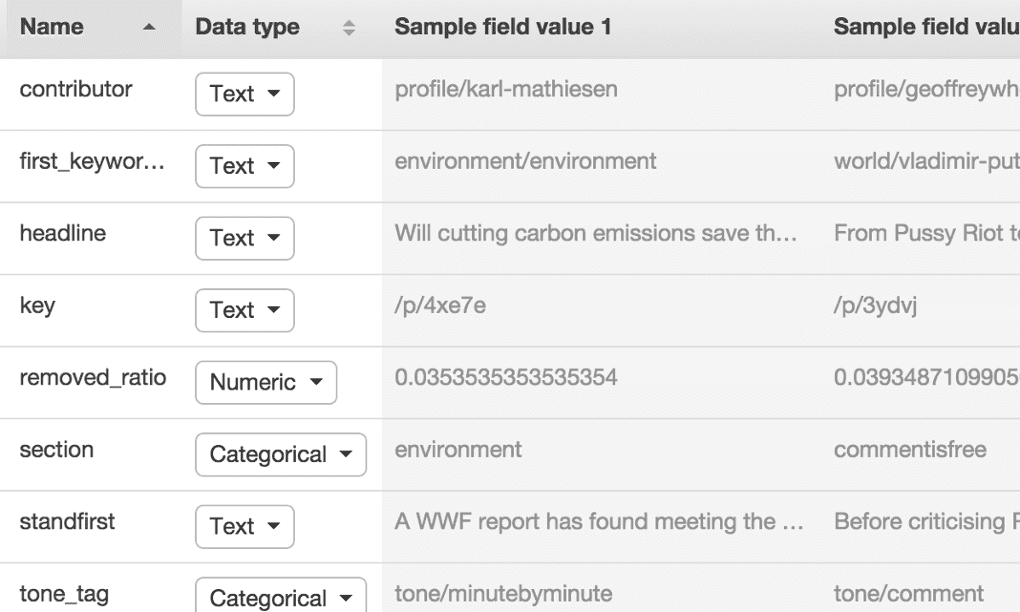
It also asks you to pick a target, i.e. the field that you are trying to predict. The type of this field decides what kind of model AML will build. In our case the removed ratio was a numeric field, so AML performed linear regression analysis to try to fit all the data points to a multi-dimensional line.
One nice feature of AML is that it supports a free text type. You can give it data like an article headline and it will take care of tokenising and vectorising the text to extract features. This process is a black box, however, so it’s unclear whether it’s using techniques such as tf-idf to weight features.
Once AML has built and trained the model, it can also evaluate it for you. It will automatically split your input data into training and evaluation data, using 70% of the records to train the model and the remaining 30% to evaluate it. After evaluation is complete you can visually explore the results, and AML will tell you how it compares with a baseline model that simply chooses the median value for all predictions.
Rather depressingly, we struggled to get better performance than the baseline model. We tried building a number of models using different combinations of features, but it turns out that most of the features we chose (headline, tags, and so on) did not have much correlation to the feature we were trying to predict. In other words, we were asking AML to fit a straight line to a cloud of randomly scattered points. As the old data science proverb goes, “garbage in, garbage out”. Interestingly, the article headline was the most useful of all the features we tried, with a correlation of 0.23759.
But just because our numbers were nonsense, that wouldn’t stop us from building a shiny demo! We wrote a simple Play app that grabbed the latest articles from the Content API, asked AML for a removed-ratio prediction for each one, and displayed them sorted by descending score.

Although the numerical performance of the model is poor, the results it picks seem intuitively pretty good. The top few results include articles about Israel, climate change and gay marriage, all of which we would expect to attract some comments that require moderation. Trying out a few predictions, the model seemed to be reasonably good at predicting outliers, understanding that articles about fluffy kittens are unlikely to attract abusive comments while those about feminism tend to garner many more, but any predictions about more ‘normal’ articles were just stabs in the dark.
In conclusion, Amazon Machine Learning is a really useful tool and we’re glad we got the chance to learn how to use it. While AWS user interfaces can be hit or miss, this one was really easy to use. It made the process of building, training and evaluating models much simpler and faster than if we were to do it ourselves using tools such as MLlib or SciPy. If we find a problem in the future that’s more appropriate for linear regression, we’d like to give AML another try.
If you’d like to see the code we wrote, it’s available on GitHub.