
In a series of posts for the Developer Blog, we’ve been exploring the role that tags play in our content management system, from building topic pages to forming a taxonomy, and how we keep them useful and in house style. In this final part, we are looking at some other roles that guardian.co.uk tags play, including linking them to the wider web.
Placing components on pages
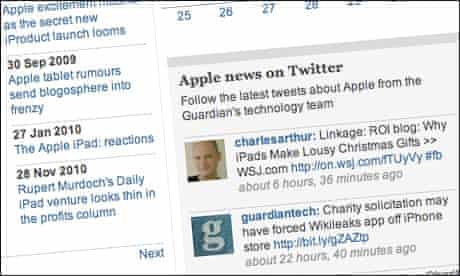
The tags attached to an article can trigger related content to appear in the right-hand column of our pages. On Technology stories tagged with Apple, for example, you’ll see a component that automatically displays the latest tweets featuring keywords like “apple”, “ipod” or “ipad” from Guardian technology and media staff such as Charles Arthur or Josh Halliday.
Article tags are used to fine tune some of the commercial inventory on our pages. If you visit articles tagged with Environment, you should be presented with a promo slot for Guardian Jobs, where the positions being advertised are relevant to those interested in the topic.
Exploring content on other platforms
Two of the distinctive features of the Guardian iPhone app are based on tags. The “Trending” page lists the tags that are on the articles currently attracting the most attention.
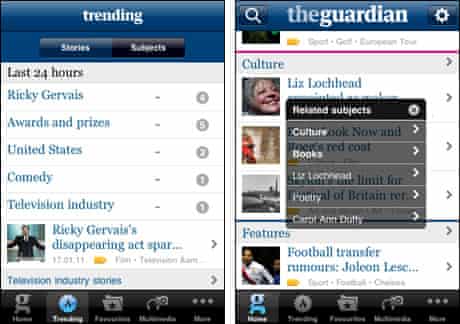
Users are also invited to explore content on the app by using the “tag overlay”. Each article headline has a small yellow tag icon underneath it. Tapping this reveals the keyword tags for that particular story. This means that a user can very quickly drill down to a specific topic within the app without having to navigate nested menus.
Improving search and navigation
Tags help us to improve the results on our site search.
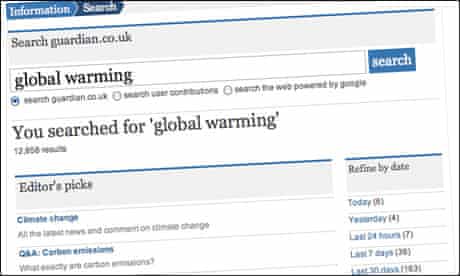
When users input terms that are synonyms or near-synonyms of topics we cover, we can return the relevant tag page amongst the top results. This means that if you search for “global warming” on guardian.co.uk, you’ll get the tag pages for climate change and the Copenhagen climate change summit up at the top.
Likewise, when there is interest in a specific person closely associated with a topic – for example, Julian Assange – we can use these tag picks to offer people the WikiLeaks page when they search for his name.
Connecting our tags to the rest of the web
A recent development with our tags has been the ability to query them using some common external identifiers via our API.
And in English?
That means you can pop an ISBN into our Open Platform Content Explorer, and it will let you know if we have reviewed the book. Or you can put in the MusicBrainz ID for The Magnetic Fields – a string of computer gobbledegook like 3ff72a59-f39d-411d-9f93-2d4a86413013 – and get back articles that are only about the band, not just any article on the website where the band or the electric phenomena has been mentioned.
This is part of a move toward using “linked open data” on our platform, and you can read more about it here: “Adding Linked Data to the Open Platform”
So metadata isn’t boring after all …?
Metadata has a reputation for being boring. However, we hope that over the course of the four blog posts you might have come to realise that adding additional metadata to Guardian and Observer content isn’t in fact a boring menial task, but something that adds real value to our content, and enhances the way that we present that content digitally.
If you want to find out more about how we ended up with the content model that we did, then in 2008 Nik Silver and Mat Wall wrote an essay on using domain-driven design in the rebuild of our content management system. It is quite a technical essay, but well worth a read to see the lengths that the technical team went to in order to make sure they understood the editorial needs and requirements of our publishing systems.