
Ophan is the Guardian’s in-house developed real time analytics tool which allows us to see how our content is performing in real-time, providing our Editorial teams with the insights they need to curate and promote our journalism. Its intuitive ways of monitoring reader engagement with content help the teams to evaluate whether it’s performing optimally.
Ophan’s distinguishing feature has always been to provide journalists with visualised real time pageview information, with features based on the previous two weeks. More recently we have expanded these capabilities to provide insights for wider timescales with years of data available at their fingertips.
This longer term feature set is referred to as “Historical Data” and seeks to provide Editorial with visibility of how a section, desk or topic is performing over time. This will empower our editors to think strategically in a data informed way. So far, we have delivered the ability to view pageview information for a specific article across years, but we have ambitions to take this further.
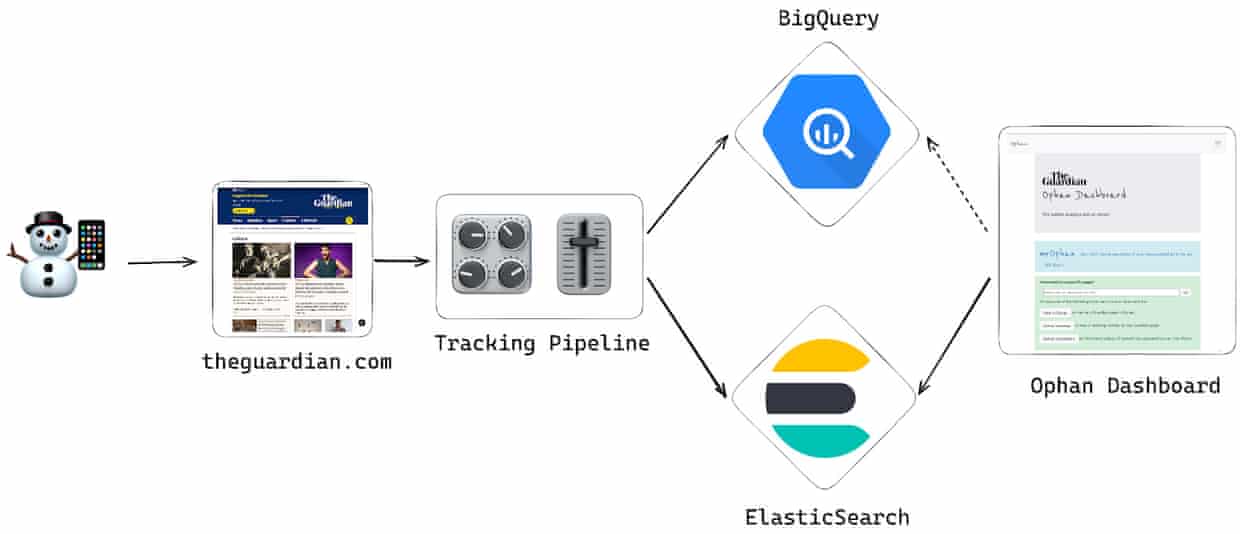
Ophan’s dashboard is primarily backed by an ElasticSearch data store, which offers the performance and capabilities we need to ingest data and surface the results quickly. The pipeline of pageview data is forked and ingested separately into our temporal ElasticSearch data store, and our BigQuery data warehouse for longer term storage.
To date, the ambitions of Historical Data has been backed by ElasticSearch Rollups, a feature designed to provide all the benefits of a search optimised data store while reducing the associated storage costs. It works by “summarising old, high-granularity data into a reduced granularity format for long-term storage.” Historical Data is a perfect use case for such a feature set; it would allow us to utilise our existing application code but simply expand the data available. What’s the catch!?

On reflection, the writing was on the wall (docs page), the feature is in technical preview. What’s more, it’s been in technical preview since March 2018. ElasticSearch fully acknowledges that the feature is not covered by their service level agreement and that it may be subject to change or even removal moving forward.
Ophan was an early adopter of this feature, given it was such a compelling use case which matched its intentions perfectly. Other possibilities, such as integrating with the data warehouse, were considered but found to be less compelling due to it requiring significant re-architecting at the time. As long as Elastic were continuing to invest in Rollups, Ophan would be a grateful beneficiary. However, over time a lack of investment became evident with significant flaws which have been encountered and unresolved.
Despite this, the team was successfully able to work around any limitations and code solutions to problems which were surely on the to-do list at elastic. For instance, see the work the team did to backfill Rollups, reverse engineering a way to generate rollup documents. In other cases, simply dropping features which were promised out of the box, such as searching across live and rollup data. Nothing that would significantly inhibit the success of what we were planning to deliver.
Then came the startling revelation, that aggregations performed against rollup documents could provide inaccurate results. In our case, we had a simple requirement: find the best performing pieces of content for a given time frame and order them by a count of pageviews. Our queries would happily return results and those results appeared to be perfectly reasonable, until we compared them with our data warehouse.
We found that under some scenarios, we received only 6% of the correct results for a Top 50 query of articles published in 2021. After carefully investigating, we discovered that these inaccuracies were in fact an implicit part of the way Rollup aggregations are performed and had been known about since 2019. We attempted to contact Elastic, but received no response, despite the acknowledgment of the problem by their engineers. This discovery forced us to reevaluate our architecture for Historical Data, despite having already invested so heavily.

Falling back to an architectural decision record format, the team decided to carefully evaluate our options, revisiting the decision making from the outset of historical data. This was an exercise which proved to be enormously beneficial. Treating our current situation as a decision making process allowed us to take a step back from our narrowly focused perspective and consider the wider opportunities available to us.
Exploring these possibilities prompted us to contact our brilliant colleagues in the Data Tech team and Data & Insights department. This team typically focuses on tooling and analysis to provide insights for the Guardian, not just for pageview data but varying datasets.
Since the time we made the decision to use Rollups, we had moved from a data lake to a proper data warehouse, using BigQuery as a serverless query engine and DBT to model and express different data transformations and aggregations.
The Data Tech team were enthusiastic about the prospect of using that stack to directly support the Ophan dashboard, being a common and well established use case for BigQuery. We found the benefits of this option enthralling, it would allow us to access more data, more freely, removing our reliance on Rollups altogether. So we began a spike to explore basing our existing functionality on a completely separate data source, BigQuery.
Working closely together, we were quickly able to set up a rudimentary integration with BigQuery, allowing our local project to run queries and return results. There were then a few core areas we needed to explore in more depth. Cross-cloud authentication, pre-aggregation, performance and query building.
After several months of development, we had overcome the initial complexities of this approach:
- Pre-aggregating data
The amount of data available in the data warehouse makes it prohibitively slow to query and aggregate on the fly. Making use of the existing pre-aggregation SQL we had developed to backfill our Rollups, we were able to set up multiple DAGs in Airflow to periodically pre-aggregate the data and populate our tables. This new approach opened up the possibilities of making greater amounts of data accessible to our users and the flexibility to change our requirements further down the line.
- Authentication
Utilising Workload Identity Federation, we were able to implement a keyless cross-cloud authentication system which allowed our instances in AWS to assume GCP service accounts providing the access necessary to query the new data.
- Performance optimisation
We optimised performance through different ways. First partitioning enabled us to reduce the amount of data being processed unnecessarily when querying. Then using table clustering we increased performance by clustering our pageview data by content identifier. Finally, by making dedicated slot reservations, we were able to offer reliable performance for the queries.
Building on this new approach, this coming quarter we are seeking to begin anew our endeavour to build out the Historical Data feature set. We will begin where we left off with top performing pieces of content in a given month, but there are a few lessons which will stick with me.
First, be wary of putting your eggs into the technical preview basket. While it may be appropriate at times to invest in technology which is not entirely finished, be prepared for the possibility that it may not come to fruition. Projects can be dropped, found to be over ambitious, or simply people move around. With these possibilities, you need to consider if it’s appropriate to use them as a foundation for your product.
Second, the importance of reevaluating your situation when new information comes to light. Having invested so heavily in ElasticSearch Rollups, it was a difficult decision to even consider other architectures. However, when you take a moment to consider the medium and long term implications of your approach, you can realise whether you’re building a solid foundation or creating more problems for yourself in the future.
Finally, collaboration. This is a story about the value of collaborating with those around you. The switch to BigQuery would not have been possible without the insight, enthusiasm and effort of engineers across teams and departments. When people work together, great things can happen.