
In a conventional continuous delivery environment, deployment pipelines are largely focused on comprehensively testing new builds against staging or UAT environments. Once all of the tests go green in the final staging environment, developers feel confident that their code is ‘production-ready’. Increasingly often, even the process of releasing to production happens automatically (in the case of continuous deployment). However, despite the sophistication of many automated pipelines, their usefulness is often considered to expire as soon as the code has been shipped.
For the Guardian’s Membership and Subscriptions apps, which allow users to register for our membership benefits and purchase newspaper or digital subscriptions, we took a different approach. Instead of focusing on lengthy validation in staging environments, our continuous deployment pipeline places greater emphasis on ensuring that new builds are really working in production. We believe that developers should derive confidence from knowing that their code has run successfully in the real world, rather than from observing green test cases in a sanitised and potentially unrepresentative environment. Therefore we minimised the amount of testing run pre-deployment, and extended our deployment pipeline to include feedback on tests run against the production site.
There is one relatively unique aspect of our codebase which allows us to operate in this way. Unlike many projects, we don’t have a separate, dedicated staging environment. Instead, our production apps are coded to dynamically switch between two separate back-end systems at runtime: one for real users, and one for special test users (which the apps can identify). This enables us to run tests against our front-end production code, without making genuine payments or distorting business results. Consequently running automated tests against each newly released app, as a post-deploy step, becomes possible.
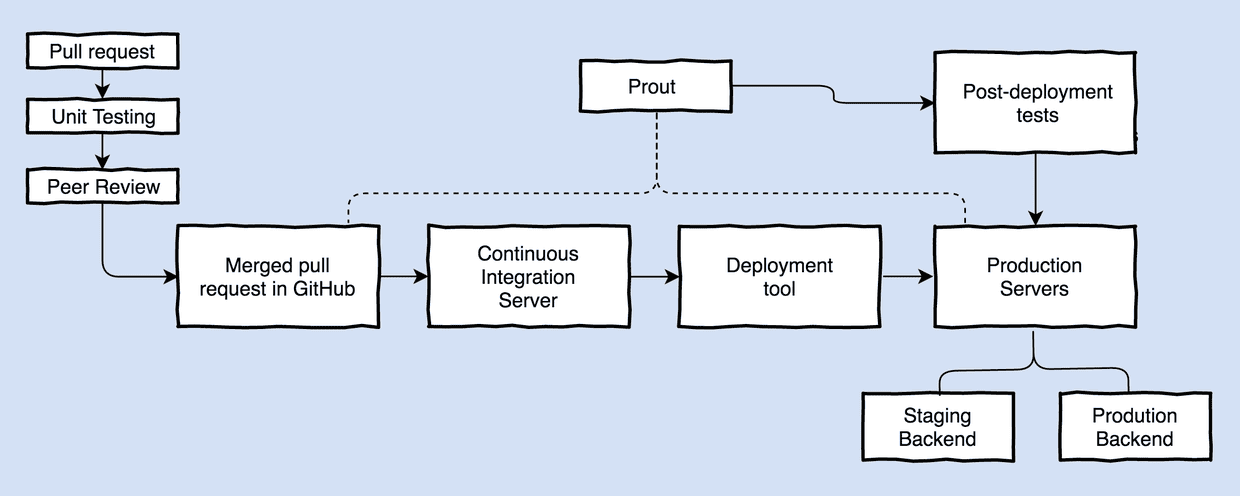
Completing the feedback loop - directly within GitHub
Here at the Guardian, all of our deployments start with a pull request being merged into master. Once unit testing completes, our in-house deployment tool kicks into gear and a tool called Prout, which monitors pull requests and informs developers when they are live, expects to see the new commit id appear on the production site within minutes. Once Prout has detected the new build, the PR is updated with labels and comments - and we are able to unambiguously assert that the code is live.
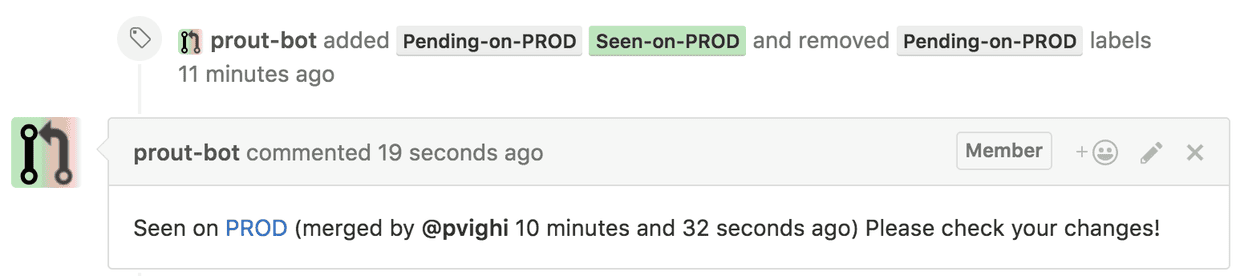
Unlike the conventional pipeline, which is satisfied at this point, our extended pipeline demands that we do not stop here; we also want to establish that the changes are working correctly in production. This is vital, because any production issues with the Membership and Subscriptions apps will frustrate our most engaged users by preventing them from signing up for our services - not to mention costing the business money. Identifying issues early is also important from a development perspective, because a developer is best placed to fix a bug in a piece of code that they’ve just been working on. Knowing that new changes are working in production is also valuable in the (much more frequent) positive case, because being informed about success so quickly after a release gives developers confidence to work at speed, as deployments become a trivial event.
Consequently, to ensure that our newly shipped code is working correctly, we use Prout to trigger some core post-deployment tests, running these directly against the front-end production app (which will dynamically switch to use the staging backend). Crucially, the aim of including testing in production as part of our re-structured pipeline is to provide feedback to the developer as soon as possible after the release. Because development teams are already used to receiving and reacting to feedback about code quality in GitHub (from code review to CI unit test execution) under a more conventional workflow, we also provide production test results directly within the pull request.
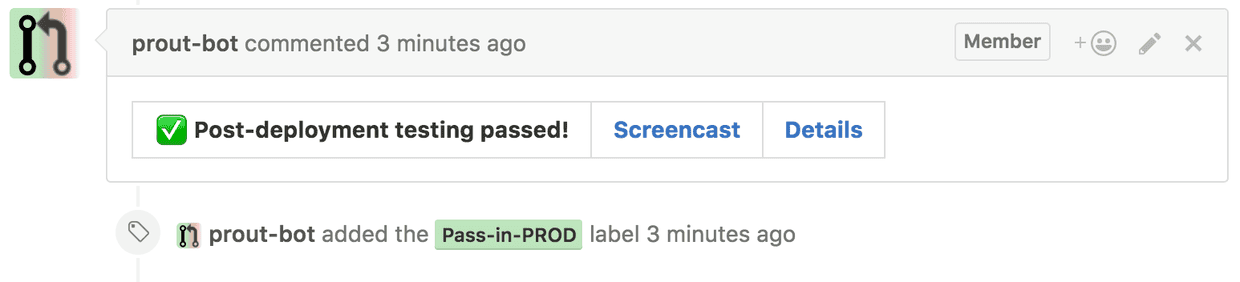
For us, this means that developers are informed that their changes are working in production within minutes of merging to master. And, should anything unexpectedly go wrong, Prout will quickly raise the alarm, allowing us to roll-back if necessary and minimise disruption to our users.
Further validation - monitoring in production
Although not part of the deployment pipeline itself, building feedback and monitoring capabilities into the apps (using tools such as Google Analytics, Sentry and AWS CloudWatch) is also vital to our approach to deployment.
These aspects of our codebase enable us to notify on successful events after a release and alert us to any new errors immediately, meaning that we can take advantage of real user data. Because we focus our post-deployment tests on only the most crucial functionality, our production monitoring is essential in order to quickly identify less common cases (a high-proportion of which would not be captured by conventional acceptance testing) - and our re-structured pipeline allows us to fix them quickly and deploy new changes with confidence.