We’ve shipped off a bunch of reporters and other Guardian staff to the SXSW festival. They have to cope with all that sunshine, fantastic Texas food, a plethora of mind-expanding panels and talks to go to and a choice of web company parties, while I stay here in the UK wrapped up in a warm slanket.
Conferences such as SXSW are well known for their over-saturated W-iFi, fights over corridor power points and whatever the mini-USB/power cable/phone charger equivalent of free love is.
Not, in other words your usual working environment – you’re not in desktop iMac country now! Instead we’ve armed them with various mobile devices, iPads, the odd laptop (for when it gets really serious) and Tumblr blogs. Rather than waiting until the evening for a full report of the day’s events (although we’re expecting those too) they can easily (in theory) upload photos, videos and short observations throughout the day, using the lightweight Tumblr posting tools, iPhone clients, email and so on, making the most of those 10-hour battery lives.
You can follow our intrepid heros and heroines over on their Tumblr blogs here: Jemima Kiss and Robbie Clutton, Rosie Swash and Lisa van Gelder, Paul MacInnes and Matt Andrews, Tim Jonze, Josh Halliday and finally Elliot Smith.
We also wanted a place on the site that would pull all those Tumblr blogs together, along with the coverage that makes its way onto our own site. That’s where I come in, and the page itself is here…
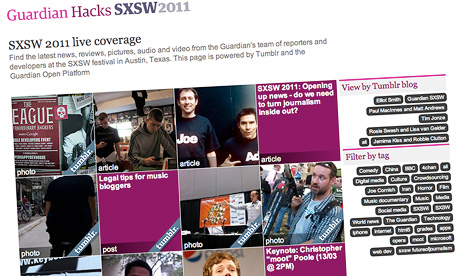
http://guardian.co.uk/sxsw/live
This being the Dev Blog, things now get slightly more techie, also there are two parts to this project:
The back end
The problem: we have a number of Tumblr blogs and a Guardian tag (culture/sxsw) we want to aggregate together. Fortunately both have an API; in the case of Tumblr we can extend the URL to give us the content in machine readable format, JSON. Here’s how it works with Jemima’s Tumblr blog…
jemimakiss.tumblr.com
…becomes…
jemimakiss.tumblr.com/api/read/json?callback=cb
For the Guardian we can use something similar to the following API call…
content.guardianapis.com/search?tag=culture/sxsw&format=json&show-tags=all
Using our Swiss army knife of automating tasks, Google AppEngine, I quickly set up a task that would cycle through each of the Tumblr blogs and our own culture/sxsw tag once a minute. It records any new posts it finds into its database. In addition if the post is a photo or video the code attempts to discover a sensible-sized thumbnail for each of them.
With Tumblr this can be tricky as people often post YouTube or Vimeo videos as well as directly to Tumblr. Each of these sites have their own discovery method. YouTube and Vimeo work roughly like this…
http://img.youtube.com/vi/\[**videoId**\]/hqdefault.jpg
http://vimeo.com/api/v2/video/\[**videoId**\].json
![http://img.youtube.com/vi/\[**videoId**\]/hqdefault.jpg](http://img.youtube.com/vi/%5C%5B**videoId**%5C%5D/hqdefault.jpg){kind=link}
The Guardian’s own content is slightly easier: if you have a registered API key you can also pass over &show-media=all as an extra parameter and the API will give you back a bunch of stuff about the images/video used.
Anyway, what we end up with is all the photos, videos, and post/article content itself tucked away in chronological order safely in the database, along with all the tags used for each item and where it came from.
The decision then is how to present it.
The front end
There was a couple of different directions I could have gone with the front end.
One, would have been to make the page look as much like a Guardian page as possible, the latest posts, photos and videos all blended in together from the various sources. This option has a lot going for it, as it would allow our reports to use the lightweight blogging tools, while we could present those reports using our own house style.
The drawback in this instance is that if you’re going to make a page look like your overall site design you really need to get it spot on, and that takes design resources. This was one thing I didn’t have, due to the timely combination of it being very last minute, and our design team already working on the rather lovely SXSW 2011 Band Tracker.
Given that it wasn’t possible to make it look very “Guardiany” this time around, it was time to go in the other direction. The direction of not-much-time-or-resources.
Squares!
Squares are good for a couple of reasons…
- They’re square. It’s pretty hard for IE to mess up squares (although believe me it tries)
- I’ve done squarish stuff before with the Zeitgeist
Both good shortcuts.
The Guardian website already uses the jQuery javascript library, giving me another timesaver. So with Google App Engine on the back end with all the posts stored in its Database and django as its “tempting language” it was fairly quick to lay out the latest 24 stories on a grid.
There was quite a bit of faffing around getting the images and video stills lined up. I tried CSS, but ended up doing the calculations needed to position them on the back end instead. Not because it’s better that way, but because I suck at CSS.
Once the layout was looking good, I used the jQuery already on the site to handle rollovers on the squares themselves, the blog titles and the tags.
There’s a couple more things that would have been nice to have: clicking on a tag to load in just stories with that tag; and the ability to go back and see older posts. And probably my favourite extra: automatically loading in new posts without needing to reload the whole page.
This last one didn’t happen as I wasn’t sure quite how often people would be updating the Tumblr blogs, if it was just once or twice a day, then it’s a lot of effort for something that probably no one would see. Having watched our trusty reporters at work I think they’re posting enough for it to probably be worth the effort … next time.
Speaking of next time, hopefully we’ll have a good look at what did and didn’t work with posting to Tumblr when we were out and about. I’ve got my eye on Glastonbury, as clearly I need to be writing this kind of blogpost from a field, in the mud, and rain.