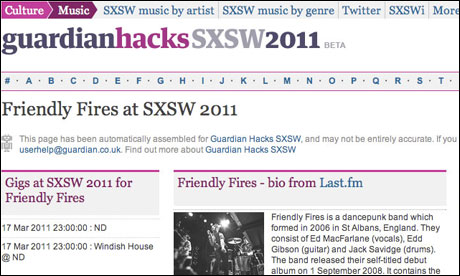
I’m going to the South by Southwest music festival this year and the listings on sxsw.com weren’t that useful. Since our listing pages were built, sxsw.com has started to include videos and sample tracks for some of its artists, but when I first visited the site it all looked like this:

I don’t know most of the bands who are playing, and the Guardian has no record of many of them. While some are established artists, there are many new artists that the Guardian hasn’t written about yet. I wanted a way to build what was useful for me – a brief description of the artist, an idea of what type of music they play, sample tracks, sample videos.
How to build pages for artists the Guardian has never heard of …
Linked Data
At the Guardian we were already thinking about how we might use linked data to improve our existing music pages and had built some sample code proving it could be done. When the GSxSW hack day came along I thought it would be fairly easy to repurpose some of that code to build fully automatic listing pages based on the SXSW data set.
The key to using linked data to build pages is that you need a universally understood identifier to ensure you are getting data for the correct entity. Luckily for music that already exists. Musicbrainz has generated ids for bands that are used by many websites and services such as BBC, Last.fm and DBpedia.
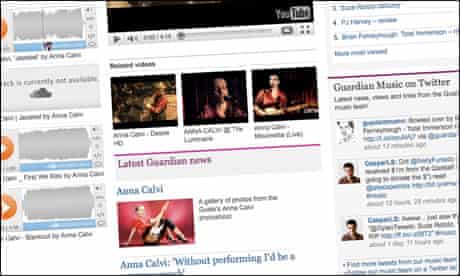
Unfortunately I didn’t have a list of Musicbrainz IDs. I had a list of artist names. So I started by scraping the SXSW music listing pages, giving me a set of bands who were playing and stored them in Google Appengine. Then I used the Musicbrainz.org API to get Musicbrainz IDs for the artists. Not all artists have Musicbrainz IDs. The ones that didn’t don’t have listing pages on the Guardian right now. Once I had the Musicbrainz ID I used the Last.fm API to find out more details about the artist - bio, most popular albums, most popular tracks, tags, related artists. Again, Last.fm didn’t have details for all artists. If they had nothing at all, the artist didn’t get an automatic page built. To pull in any articles the Guardian has on the artist, Ivan Codesido wrote a component that queries the Guardian content API for artists with an external reference of that Musicbrainz ID. If you look at Anna Calvi’s page for example, there is a list of Guardian articles about her at the bottom.
Not all artists we have written about are tagged with a Musicbrainz ID, that will improve as time goes on.
Search by artist name
Ivan and I also wanted to pull in tracks and videos, and both YouTube and Soundcloud have APIs that make searching for artists easy. Unfortunately they do not allow search by Musicbrainz ID, so the data we get back from them is based on artist name. Ivan wrote a component that queries YouTube based on the band name and returns a set of videos. When the artist has a unique name or is well known, the YouTube component works brilliantly. For others the videos returned may not belong to the artist at all. The Soundcloud tracks are the same.
If no API exists, write it yourself
Gigs - Showcase times are starting to be listed on the SXSW site but they are not easy to scrape. sxsw.com has one line for each artist and gig pairing – if an artist plays three gigs they are listed three times on the same page (this also caused me to import duplicate artists by accident).

To make it more difficult, the information about each gig (time, venue) is on a different page which would mean making another separate web request for every artist. Matt Andrews scraped the gig data and wrote an API that returned a list of gigs for a Musicbrainz ID. You can see the result in the top left corner of our listing pages.
In the second part of this post later this week, I’ll look at some of the problems caused by automatically generating pages on an editorial site such as guardian.co.uk, and what we did to solve them.