
A few months ago we wanted to explore making the Guardian’s website available as a Tor Onion service, a service that can only be accessed over the Tor network. Guardian readers have always been able to access https://www.theguardian.com over Tor using tools such as the Tor Browser. The Tor network helps conceal its users’ locations, which makes tracking their internet activity much more difficult. Tor also makes it harder for internet service providers to identify what their users are accessing. This means users can bypass censorship in parts of the world where access to independent news might be difficult or if certain websites and services are banned. Onion services go a step further, ensuring the end-to-end communication is conducted entirely over the Tor network (more on this in the next section.)
As always in Guardian product and engineering, our ambition is to rapidly deliver something of value to our readers, learn from any feedback and iterate over time. But with a relatively unfamiliar technology, which doesn’t align perfectly with many of our common tools and patterns, we faced some different challenges. In this article we’ll share these challenges and our approach.
If you’d like to browse the Onion service, you can visit https://www.guardian2zotagl6tmjucg3lrhxdk4dw3lhbqnkvvkywawy3oqfoprid.onion while using the Tor browser.
Onion services
Accessing a website on the “clearnet” (the regular internet), even using Tor, relies on domain name resolution and IP-address-identified servers where the website is hosted. The final communication between the hosting server and the server attempting to connect (whether it’s your own computer or a Tor exit node) uses regular TCP/IP to route packets. This opens the door to potential man-in-the-middle attacks and also reveals the location of the hosting server to the connecting server via its IP address. For some hosts, who wish to remain anonymous, location-hiding is the primary reason for using an Onion service. For the Guardian, that aspect is inconsequential; we want to provide anonymity for our users, not ourselves.
On the other hand, an Onion service is identified by its public key; IP addresses are not even used in the protocol. For instance, the Guardian Onion service’s address is www.guardian2zotagl6tmjucg3lrhxdk4dw3lhbqnkvvkywawy3oqfoprid.onion. Instead of IP routing, in the Onion service protocol a client will introduce itself to a service, and then communicate via a rendezvous point over the Tor network. For a more detailed explanation of this process we recommend reading “How do Onion Services Work?” on the Tor project website.
Discoverability and trust of Onion services is a key difference to clearnet websites. How do you know when you visit the long .onion hostname that it is really the Guardian providing that content? How do you find it in the first place?
You could publish an article on your site, such as this one, that advertises the address. Or you could include a reference in your certificate or DNS records for your clearnet domain. None of these options is particularly visible, but happily the Tor browser provides a feature for Onion service owners to advertise them when users visit their clearnet site. Including an Onion-Location HTTP response header will enable a banner to appear in the address bar indicating the availability of an Onion service.

The Enterprise Onion Toolkit
Often the simplest way to host an Onion service for an existing website will be to host it as a proxy. Your Onion service responds to requests by forwarding them to your existing backend, meaning you don’t need to create a duplicate of your website rendering tier, when it will mostly function the same anyway.
However, this kind of proxy for an Onion service does need to be a little smart. If we simply served the usual theguardian.com pages, many of the links and assets would point to theguardian.com, making it difficult for users to navigate around and stay exclusively on the Onion service.
Fortunately we are not the first to address this challenge. In fact, there is an excellent toolkit for setting up exactly this kind of proxy called the Enterprise Onion Toolkit (EOTK). The EOTK is an open source toolkit for bootstrapping proxy-based Onion services for publicly available websites. It provides scripts for installing the necessary software to host a service, as well as a command-line interface for configuring, and orchestrating the proxy. Under the hood it relies on the popular web-server Nginx (in particular OpenResty), as well as Tor. Nginx acts as our proxy and URI-rewriter, while Tor is used to connect this proxy to the Tor network as an Onion service.
Architecture and configuration
The Guardian predominantly uses Amazon Web Services (AWS) as our cloud provider. In recent times we have been leveraging their cloud development kit (CDK) to build our own Guardian-flavoured library of CDK patterns, in Typescript, for infrastructure definition. CDK allows developers to define their AWS resources using familiar programming languages. By reusing our own specific patterns, we are managing to improve consistency, security and operational best practice, while freeing up teams to focus more time on developing their applications, not the infrastructure behind them.
For our Onion service we decided to leverage one of these patterns, which enabled us to spin up a fully fledged EC2 based app in very little time. An abridged, annotated version of our configuration can be seen below.
new GuEc2App(this, {
// restrict the access scope of our app to be VPC-internal
access: {
scope: AccessScope.INTERNAL,
},
// user data is the script run on instance launch
userData: [
“#!/bin/bash -ex”,
// copy keys for our onions from S3
“cd /usr/local/eotk”,
`aws s3 sync s3://${bucketName}/theguardian.com/onion/ ./secrets.d/`,
`aws s3 sync s3://${bucketName}/guim.co.uk/onion/ ./secrets.d/`,
// define EOTK configuration for our site
“cat > theguardian.conf <<-EOF",
"set project theguardian",
// block all subdomains except www and static
`set block_host_re ^(?!www\\.|static\\.).+${guardianHostname}\\.onion$`,
// map our mined Onion addresses to their respective sites
`hardmap ${guardianHostname} theguardian.com`,
`hardmap ${guimHostname} guim.co.uk`,
"EOF",
// use the EOTK CLI to set up the necessary config
"./eotk config theguardian.conf",
// copy our certificates to the required location
`aws s3 sync s3://${bucketName}/theguardian.com/ssl/ ./projects.d/theguardian.d/ssl.d/`,
`aws s3 sync s3://${bucketName}/guim.co.uk/ssl/ ./projects.d/theguardian.d/ssl.d/`,
// start the onion service!
"./eotk start theguardian",
].join(“\n”),
});With the above definition, a whole slew of resources are created for us including an autoscaling group (ASG), a load balancer (VPC internal), security groups, IAM policies/roles and monitoring alarms. There are some built-in assumptions, relating to communication protocols, in the GuEC2App pattern we used, which means some of the resources or configurations are redundant for an Onion service. For example, a redundant certificate is created and the load balancer serves no requests except for health checks. We felt this was a worthwhile trade-off for the simplicity and consistency of the implementation.
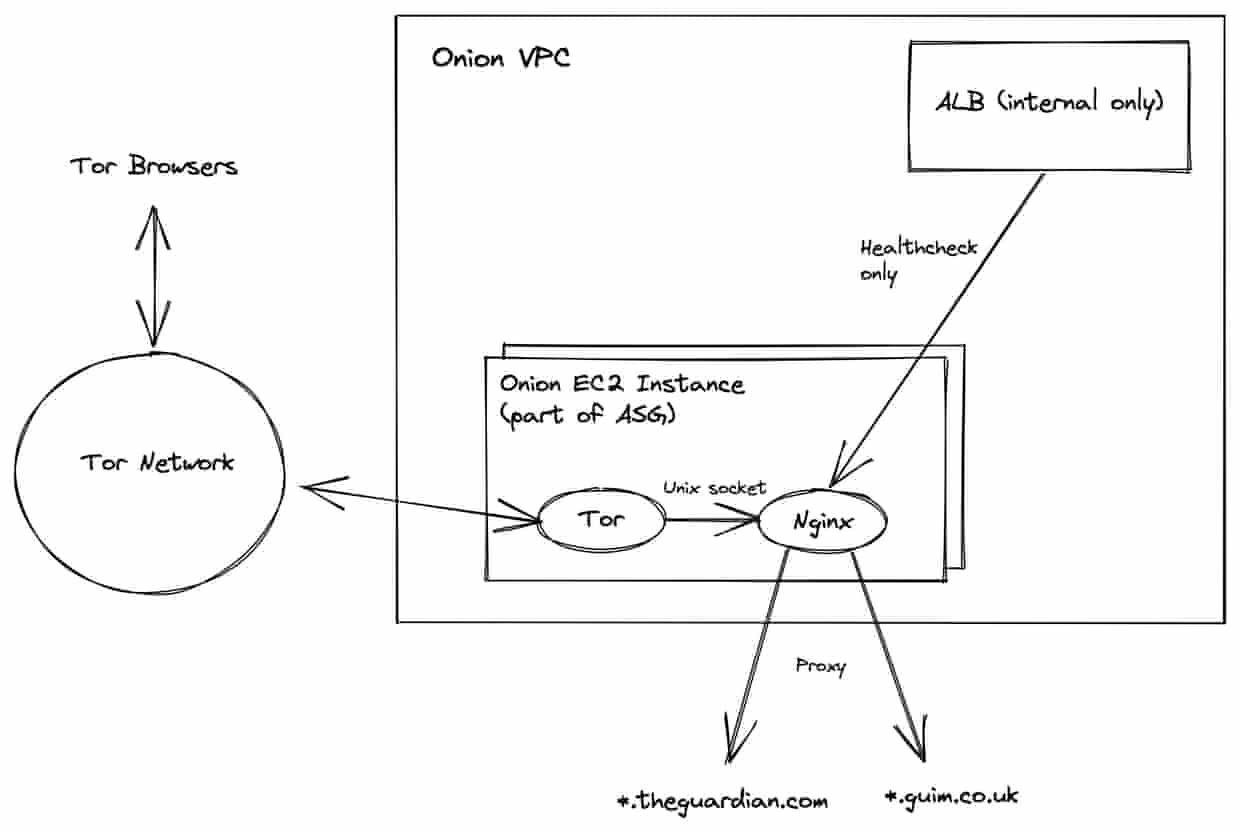
You may notice that this configuration does not include any installation of Nginx or Tor. Best practice dictates that such software is installed prior to instance start, so that launches are faster and more predictable. At the Guardian, we do this using AMIgo, our tool for managing custom Amazon Machine Images (AMI). For this project we simply defined a new EOTK (Ansible) role that runs EOTK’s installation script for our chosen operating system and regularly creates a new AMI from its output. The latest version of this AMI is then passed to our CDK definition via a parameter that gets updated on a schedule, in order to apply security patches.
Another feature worth mentioning is the use of static, mined Onion addresses, which we specified using hardmap in the EOTK configuration file. EOTK is able to generate Onion addresses on the fly, using softmap, but to give our readers a consistent and somewhat recognisable URL, we mined addresses until we generated the public/private keys for addresses starting with “guardian”. We launched our service using one of these key pairs.
Limiting functionalities
We consciously decided to remove some features from our website for readers accessing it via the Onion service.
Sign-in and consent
Tor users will not be asked to sign-in to access our content for two reasons. First, most people using Tor are seeking to make themselves anonymous. This means they will aim to minimise digital breadcrumbs that may identify their web browsing activities, and asking them to sign-in would increase their chance of being identified. For the same reason, we will never use or share their personal data, so we do not ask those users for their consent to do this. Secondly, protecting sign-in and sign-up pages from bots may require us to use technologies that may identify IP addresses from Tor as being suspicious or simply prevent access to them.
Third-party advertising
Tor users will not be shown third-party advertising as it requires consent to share data and could have reduced their privacy. More generally we made the decision to disable all client-side scripts whether they are first-party or third-party. We felt that disabling scripts provided an extra layer of protection from any possible tracking that might occur once a browser visits the site, and that the typical visitor to our Onion service would disproportionately value this. Some Tor users already disable scripts for security reasons, so by disabling them ourselves we aimed to ensure everyone has the same experience and level of protection. This is helpful as well to provide a better experience as downloading multiple script files over Tor typically takes longer than on the regular web. By relying on our modern server side rendering tier without client side scripting we mitigate the slower speed load time sometimes experienced when browsing using Tor.
Displaying a message about unavailable features
To achieve this on our Onion service, we utilised some of the many built-in configuration options of EOTK. Firstly block_host_re, which was shown earlier, allows you to block particular hosts matching a regular expression pattern. We also (mis)used preserve_csv to replace some other specific links and attributes with EOTK directly. This setting is primarily intended for preserving hostnames in your content that would otherwise be automatically replaced by EOTK (think email addresses.)
There’s a good argument that you should instead implement at least some of these changes as part of your underlying site, rather than using the toolkit to alter content on the fly. That is easily achieved by checking a X-From-Onion HTTP header sent by EOTK, but would have implications on the cacheability of the requests.
In our case, we decided to avoid any cache splitting by not altering the response for a request to theguardian.com whether it comes from our Onion service or not. This has the additional benefit of keeping the underlying rendering logic simpler, if only marginally.
Teething issues
Disabling all Javascript from loading on our Onion service has implications for some parts of our content, particularly complex interactive and video content, which will not work as expected.
To prevent the loading of scripts, we set the Content Security Policy (CSP) so that scripts are disallowed from all sources with script-src ‘none’. To override this HTTP header we have forked EOTK, allowing us to directly set the value using Nginx.
ngx.header[”Content-Security-Policy”] = “%CSP_OVERRIDE_VALUE%”Apart from the aforementioned content problems, disabling scripts caused two further unexpected issues. In our first attempts to configure the Onion service, we observed unusually large gaps between stories on the front pages and a complete absence of styling on the footer of some pages. As it turned out, these were attributable to two distinct issues in the way we treated the loading of CSS in the absence of Javascript. Without getting into the unnecessary details, we will share some of the things we learned during this process.
Firstly, ensure you revisit assumptions about which CSS rules are applied when feature detection isn’t available. Browser support for CSS features is always improving, so you need to revisit these decisions in the long run. In our case, in the absence of Javascript, the legacy rendering tier of our website was assuming the browser was not supporting Flexbox and removing these rules. We fixed it by making the opposite assumption, that Flexbox is supported.
Secondly, using a CSP to disable script loading, does not mean that noscript elements are inserted into the page, unlike disabling Javascript via your browser settings. In our case, we were using a fallback noscript element as part of a method to asynchronously load non-critical CSS, but with our CSP neither the primary Javascript or fallback were being triggered to load the CSS and we were ending up with an unstyled footer. This was fixed by loading the CSS synchronously in our Onion service.
Certificates
Choosing to add TLS certificates to an Onion service is not as obvious a decision as it would be for a regular site. Tor’s protocol for Onion services means that you already have all the security benefits of HTTPS, without the need for a TLS certificate. On the other hand, many of us are conditioned that seeing https:// in our browser’s address bar is a good thing – even the Tor browser itself warns you if an Onion site has an invalid certificate, despite the connection still being secure.
Many other popular Onion services choose to use TLS certificates anyway, and we decided that it was worthwhile too. At the time of writing there are only two certificate authorities (CA) that issue certificates for .onion addresses, DigiCert (Extended Validation), and HARICA (Domain Validation.) We ended up using HARICA for our certificates.
The process for validating .onion certificate requests is a little different to usual and worth touching on. Typically, in order to validate that you are the owner of a domain, a CA will ask you to add additional DNS entries, respond to an email to that domain, or serve a specific piece of content from a specific location on that site. However, as we have already mentioned Onion services don’t even use DNS.
The CA you choose for your .onion certificate will explain the available options, but in our case for a wildcard .onion certificate the only option given by HARICA was to provide a certificate signing request (CSR) signed by the key of our Onion service. This was a little bit more involved than the traditional methods, perhaps due to the relatively basic tooling. When you think about it, though, it’s a neat reuse of an existing property of Onion services; proving you own the private key is the basis of an Onion service and we simply prove that again to the CA by signing our CSR.
Monitoring
Ensuring our Onion service is always available to our readers also proved an interesting challenge. Familiar tools for determining the health of a service, such as application load balancer health checks or uptime monitoring tools don’t typically support Onion services.
Instead we decided to build our own simple monitor using crontab, curl and CloudWatch metric alarms. On a separate service, we use curl’s support for a SOCKS5 proxy to connect via Tor to our Onion service. Running this on a schedule using crontab and sending any failures to a custom CloudWatch metric, off which an alarm is based, allows us to only trigger alerts if a certain number of failures occur within a given interval. This feature is especially important for an Onion service, because the Tor network can be less reliable, so we want to have more evidence of a problem before alerting.
The pertinent part of the shell script we run to achieve this is when we run the curl command, shown below. This command is part of a script executed by crontab every two minutes.
curl -s -S --head --socks5-hostname 127.0.0.1:9050 “$HOSTNAME” || \
/usr/local/bin/aws cloudwatch put-metric-data --namespace $METRIC_NAMESPACE --metric-name $METRIC_NAME --value 1We also found this method useful for determining when Tor had finished initialising on instance startup. We run a curl request in a loop until it is successful, but this time point it at a host we can usually rely on being able to access over Tor.
until $(curl -s -o /dev/null --head --fail --socks5-hostname 127.0.0.1:9050 https://check.torproject.org); do
printf ‘Tor not yet initialised, trying again’
sleep 3
doneLoad balancing and redeployments
As already discussed, the physical load balancer in our deployment is partially redundant; it is an HTTP load balancer for an application that doesn’t use HTTP. So how do we achieve any kind of horizontal scaling or high availability in our setup?
It should first be noted that there is an oft-quoted solution for achieving load balancing of Onion services, Onionbalance. The caveat to this section is that we did not explore this solution further because its compatibility with EOTK was unclear.
In our setup, we can simply scale out our ASG, and an extra instance of the Onion service will publish its descriptor to the Tor directory. We have observed that under this scenario, clients will begin to use all of the instances, forming a basic kind of load balancing. Unfortunately the opposite action, removing an instance from the ASG, leaves clients communicating with an instance that no longer exists (for roughly 15 minutes.) Presumably we need a way for the descriptor of that service to be removed from the directory on demand, or a shorter TTL on the descriptor, but we haven’t yet found a way to solve this particular issue.
What’s next?
By design, it is harder for us to understand the details of how visitors are interacting with our Onion service, but we are always looking for feedback to inform what we do next. For a project like this, that perhaps won’t receive as much developer time as some of our other platforms, we’re particularly conscious of putting time and effort into ensuring it has stability and longevity. As such, near-term improvements are more likely to be in the area of observability or automation. We’d love to hear from you if you’ve solved some of the challenges we encountered.
Finally, our thanks to Alec Muffett for all of the work in creating EOTK, and helping us with our particular deployment of it. It is what made this project possible. Thanks also to the assistance of other teams and individuals at the Guardian for their domain expertise with Tor and our website rendering.
Development of digital products is central to the Guardian. You could be building the products that showcase our progressive and independent journalism, crafting the tools that journalists use to write their stories, developing the services that allow those stories to be distributed across the globe, or safeguarding our financial future.
If you’re interested in joining our product and engineering team, please visit the Guardian News & Media careers page.