
Is the royal family always impartial when it comes to the formation of UK law, or could they be influencing legislation in matters that affect their interests? For months Guardian journalists David Pegg and Rob Evans submerged themselves in the National Archives, sourcing information on the archaic convention known as Queen’s consent.
Previously seen as a formality, Queen’s consent occurs when parliament asks for permission to debate bills that could affect the interests of the crown. This consent is recorded in Hansard with phrases such as “Queen’s consent signified”. Through painstaking work, David and Rob had compiled a list of parliamentary records that contained that term. Their question to us developers was: how could we use digital means to find out if their list was complete?
The Hansard website is an archive of UK parliamentary debates. Searching it is straightforward and quick. It even looks nice, like the best government websites. It was reliable and stable, even in the face of what we were about to put it through. You simply type in your search term and it shows you the transcript where that phrase was said.
Documents containing “Queen’s consent signified” and “Prince of Wales’s consent signified” were easy to find. Other cases were trickier, with phrases such as “we have it in command from” the Queen or Prince Charles that they have “consented to place” their prerogative or interests so far as they are “affected by the Bill” at the disposal of the house. An eager assistant, the Hansard website allows “AND” between search terms, so we could combine phrases and see only those results that contain them all in the same reading.
These searches gave us back 4,684 results, spread over more than 150 web pages each showing 30 results.
I understood why David and Rob had come to us: the work of cleaning up these results manually would be tedious and error-prone.
It was time to fire up one of the most useful tools in a news nerd’s arsenal: the web scraper.
Have you ever right-clicked on a webpage and pressed the “View Page Source” button? You’ll see the HTML building blocks: the mark-up incantations used to build the page on your screen. The HTML focuses on presentation: what colour that text should be, how big that image should be, and so on. Web scraping is the art of transforming this semi-structured soup back into the structured data that produced it – in this case, who was speaking in which chamber at what time, and what did they say.
In the Investigations & Reporting team, working with journalists, this often means putting the results in a spreadsheet.
There are lots of web scraping tools. During the 2019 UK election campaign, data journalist Pamela Duncan had taught us about webscraper.io. It runs as a browser extension and lets you point and click to build up the data you need from the webpage. You can see the JSON definition of our Queen’s consent scraper here. As software developers, we were comfortable coding up web scrapers with libraries such as Puppeteer, but this was a perfect opportunity to learn something else. We build effective tools by learning from those that are already available.
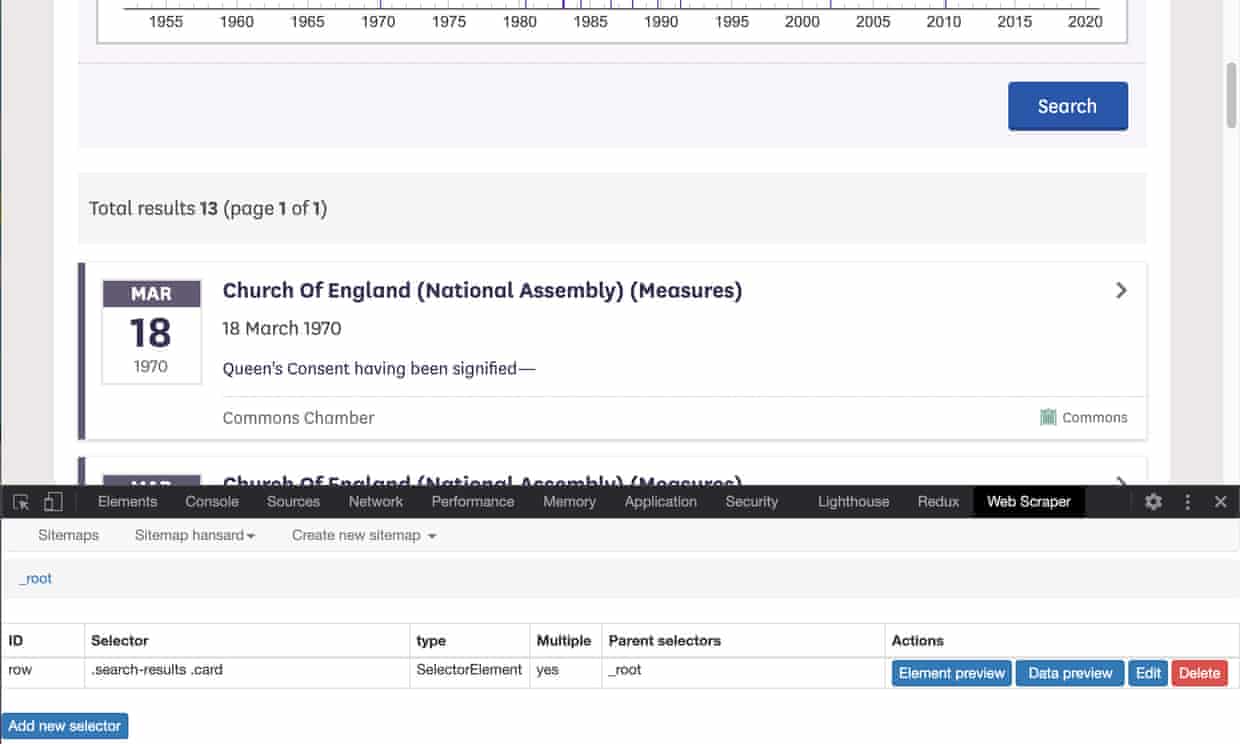
Click “Export as CSV” and you’re in business! Practically every time anyone had uttered those phrases in parliament was now in a spreadsheet.
But we weren’t done. David and Rob wanted to know how many bills had been subject to this procedure, which meant deduplication. 4,684 results did not mean 4,684 bills because the same bill could appear multiple times and in both chambers. For each entry in our raw data, we needed to group them by the bill title, date and which chamber (Commons or Lords).
For this process we turned to Athena. Much like the Hansard website, it’s a simple but powerful piece of software. We use it to get the precise and reproducible analysis of SQL without having to worry about maintaining our own database servers.
To be comprehensive, we scraped each search term individually and then deduplicated it all with a query. You can see the queries we used here.
From those results, Rob and David delved back into the data. We had reduced the data enough that they could spot check every entry, allowing us to fix typos and triple-check our working. We even found some more bills that we’d missed the first time around. We used source control to keep, review and collaborate on our queries for each project and get as many eyes as possible on our spot checks and data quality discussions. This process got us to the headline figure of 1,062 parliamentary bills that have been subjected to Queen’s consent during Elizabeth’s reign.
The work showed us what developers were able to achieve by being involved early in an editorial project. Sure, we automated away the boring stuff. But we’d also given David and Rob a batchful of fresh leads and given the story a nice kick. We’re only just starting to scratch the surface of how developers can help reporting.
A couple of days later, our colleague Colin King excitedly showed us his new spreadsheet of App Store ratings for Guardian apps. Inspired by our use of webscraper.io, he’d built his own scraper to keep track of things. We learn daily in this team that when we make time for ad-hoc collaborations between developers and others from across the Guardian, our reporting wins and the business wins.
If you’d like to read more about the work of the Investigations & Reporting team, check out our blog posts on environmental reporting, election coverage, and Covid-19 investigations.