
Recently, we decided to upgrade the Elasticsearch cluster powering the Content API. Elastic had released version 7.1, which is where we wanted to be. At the same time, Elastic deprecated the Java client we were using to talk to Elasticsearch. We had several options before us: use the low-level REST client, the high-level REST client or switch to a Scala-based library like Elastic4s. None of these options were entirely satisfactory, but we eventually chose to go with the high-level client which was designed to be very close to the Java client. Indeed, the amount of work needed was quite small and, credit where credit is due, well-documented by the Elastic team.
After a perfect roll-out, we noticed a substantial spike in our data transfer costs, and it was interesting to figure out its origin and a solution to that problem. That it happened right after the upgrade seemed too much of a coincidence, so we began investigating.
A quick lookup in the AWS Cost Explorer helped us isolate the spike to be caused by traffic between our ES cluster and the application providing the client facing API that people are used to when they interact with the Guardian Open Platform. We did everything by the book, we were sure there wasn’t a bug in our code, so we zoned in on the switch to the new client.
The obsolete Java client uses a proprietary protocol and a binary format to exchange data with ES nodes — the same used for communication between nodes — but the new client uses HTTP as its protocol and JSON as the data format. What wasn’t clear at the time, came as a sudden realisation that with HTTP – user agents must indicate how they would like content to be encoded by means of the Content-Encoding header. If they don’t, content will be sent in plain text. Spoiler alert: the ES REST client doesn’t supply any Content-Encoding header by default. We were not the only ones to notice.
With that, we had a pretty solid hypothesis and started thinking about a solution. The natural first idea was to enable compression. As the REST client uses Apache’s async-http-client under the hood, it is a matter of setting things up at initialisation time:
val hosts: List[HttpHost] = ???
val client = new RestHighLevelClient(
RestClient.builder(hosts: _*)
.setHttpClientConfigCallback(new RestClientBuilder.HttpClientConfigCallback {
def customizeHttpClient(httpClientBuilder: HttpAsyncClientBuilder): HttpAsyncClientBuilder =
httpClientBuilder.addInterceptorLast(new RequestAcceptEncoding())
})
)There is some additional complexity to handle, due to the fact that the Apache client does not support transparent decompression. In a nutshell, decompression has to be done at the point of use, by taking the entity out of the ES response object and unzipping it. This is how elastic4s does it.
The same change in our code would have been trivial. However, we took a moment to think about the issue. While we made the assumption that costs increased due to the spike in the volume of our traffic, we didn’t really identify why we were paying in the first place. The fine print on the pricing page for EC2 data transfer states, “Data transferred between Amazon EC2, Amazon RDS, Amazon Redshift, Amazon ElastiCache instances and Elastic Network Interfaces in the same Availability Zone is free.”
We had two options, to either use compression and reduce costs, or swimlane traffic so that it never crosses AZ boundaries and remove data transfer costs once and for all — or do both. We decided to explore the second route first, since we were afraid of adding too much overhead for content compression/decompression.
Here’s a rough layout of the Content API:
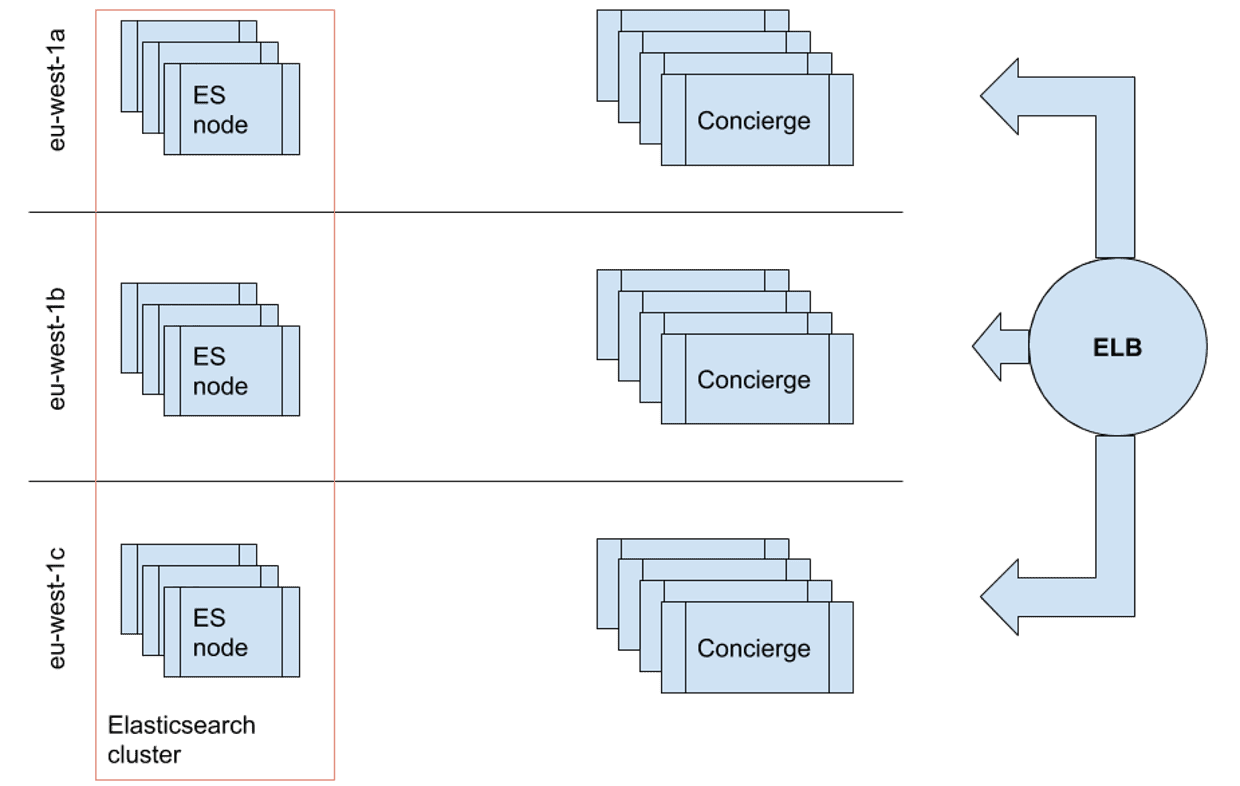
Concierge is the name of the application I mentioned earlier. Each instance maintains open connections to the ES nodes in the cluster. The REST client is not trying to be clever here, whenever there’s more than one node, requests are dispatched to each in a round-robin fashion. So, let’s address this … we not only had a cost motivation, but also, the load-balancer is already dispatching requests using a more sophisticated routing algorithm; by using RR behind it, we were kind of ruining all of that.
Right, here’s the plan of attack:
Ensure all content is replicated in each AZ
Elasticsearch is a distributed application where each data node contains units of storage (shards) which contain all the content produced at the Guardian. Fortunately, it gives us the ability to determine how those units are spread and replicated. At a minimum, then, we must have two replicas for each shard, for a total of three, one in each AZ. This was already the case for us, but if it were not, all we would have to do is update the settings for each index in the cluster, e.g.
curl -X PUT "localhost:9200/<index>/_settings" -H 'Content-Type: application/json' -d'
{
"index" : {
"number_of_replicas" : 2
}
}Ensure proper shard distribution
It is not enough to have replicas, one must make sure shards are physically distributed correctly over the network. This is achieved with shard allocation awareness.
We are using the EC2 discovery plugin to handle cluster formation in AWS. Luckily, it can tag an instance with an attribute, aws_availability_zone, to identify in which AZ it is. This is done in the Elasticsearch configuration:
# let the EC2 discovery plugin add the aws_availability_zone attribute to the node
cloud.node.auto_attributes: trueAll we have to do next is use that attribute in the shard allocation awareness algorithm. This is also specified in the configuration:
# let ES distribute shard according to that attribute
cluster.routing.allocation.awareness.attributes: aws_availability_zoneConnect clients to nodes within the same AZ
The cluster is now correctly setup. The next step is in Concierge – it can only connect to Elasticsearch nodes in the same AZ. To get that list of hosts, we use the EC2 API. For example:
def findElasticsearchHostsInEc2(client: Ec2Client, az: String): List[HttpHost] = {
val request = DescribeInstancesRequest.builder.filters(
Filter.builder.name("instance-state-name").values(InstanceStateName.Running.toString).build,
Filter.builder.name("availability-zone").values(az).build,
...
).build
val response = client.describeInstances(request)
val instances = response.reservations.asScala.flatMap(_.instances.asScala)
instances.map(i => new HttpHost(i.privateIpAddress, 9200, "http"))
}Ensure we can scale the cluster up and down
In the event where we need to scale up or down, we want Concierge to automatically update client connections. The Elasticsearch client provides a node sniffer which does exactly that.
The default implementation uses the node info API, which cannot help us here as it doesn’t know anything about availability zones—and it doesn’t seem possible to restrict a query using node attributes. That’s OK, we can just provide our own, for example:
val nodesSniffer = new NodesSniffer {
override def sniff: java.util.List[Node] =
findElasticsearchHostsInEc2(ec2Client, availabilityZone)
.map(new Node(_))
.asJava
}
val sniffer = Sniffer
.builder(esClient.getLowLevelClient())
.setNodesSniffer(nodesSniffer)
.buildAnd voila!
So free we want to buy more
With the above changes, we get all the traffic between Concierge and Elasticsearch, our most expensive cost center, for free!