
Being part of a DevOps team often means having to deal with unplanned or unexpected errors in production. In fact, a big part of our job is to make our applications resilient to outages, and as such, we need to take outages into account when designing our applications. In today’s article we’ll look into one such production incident, and what we did to improve the situation in the future.
I’m part of the mobile team and we recently experienced an outage due to a failure on one of our primary databases. We use Amazon’s RDS (Relational Database Service) to store our data in a PostgreSQL database. If you’re unfamiliar with RDS or PostgreSQL, all you have to remember is RDS is the service provider and PostgreSQL is the type of database.
We’ll dive into how the incident happened and what we can do to attenuate the effects of such an incident in the future, but before we do let’s go over a few concepts that we’ll need later.
RDS fail-over and connection pools
If you know what a fail-over or a connection pool is, you can safely skip to the next section, if you don’t let’s define them.
A fail-over happens when RDS can’t keep the primary database alive for some reason such as a network failure, hardware failure, crash… RDS then promotes a copy of that database as the new primary database. That copy is in fact kept warm and up to date for the sole purpose of being promoted in case of an incident (If you’re interested here’s the documentation). This process usually takes about 30s to two minutes.
Once promoted, that copy becomes the primary database and gets to execute all the SQL requests.
Now, let’s talk about connection pools. A connection pool is a set of network connections kept connected to a database for the purpose of executing requests without having to create a new connection for each request. Once the application needs to execute a request, it checks if a connection is available in the pool and uses it to send the request.
If you use a relational database, chances are you are using a connection pool to access the database.
The most popular connection pool at the Guardian is called Hikari as it is the default connection pool used by the Play framework. In my opinion, it’s probably the best connection pool available for the JVM.
What happened
Over the weekend our primary production database experienced a network failure. Again, this is expected and we should plan accordingly.
The database failed over as it should, and most of our stack recovered swiftly.
Except one of our services (an application built with the Play framework). This had little impact on the overall service, but it’s still an issue. Looking at the logs and CloudWatch metrics it quickly became apparent there was a connectivity issue between our application and the database.
What happened is that all the TCP (Transmission Control Protocol) connections of the pool got into a sort of “zombie” state: broken yet not closed. The reason for that is the postgreSQL driver does not set a TCP timeout on the connections. The pool never attempted to close the connections and create new ones, yet no data would come in or out of these connections. The Hikari documentation describes the problem like this:
The reason that HikariCP is powerless to recover connections that are out of the pool is due to unacknowledged TCP traffic. TCP is a synchronous communication scheme that requires “handshaking” from both sides of the connection as packets are exchanged (SYN and ACK packets).
When TCP communication is abruptly interrupted, the client or server can be left awaiting the acknowledgement of a packet that will never come. The connection is therefore “stuck”, until an operating system level TCP timeout occurs. This can be as long as several hours, depending on the operating system TCP stack tuning.
From the point of view of the connection pool, all the connections were fine but for the newly promoted database there were no incoming connections from the application. It took the application six hours to eventually fail, with new servers coming online the database access was restored and everything went back to normal. This is far from ideal.
Reproducing
I managed to partially reproduce the issue in our test environment using the RDS console. It’s hard to reproduce a hardware or a network failure. In the RDS console there is an option to reboot the instance with a failover. Using that option while having a moderate amount of traffic to the service I managed to get a few of the connections to reach the same state we had in production. This contrasts with our production incident where all the connections reached that state at the same time, but it doesn’t matter here as we only want to prove the pool can recover.
After a few database reboots (6), I saw the number of connections to the database going down. In other words, connections were dropped but our application still thought everything was fine and no further connection attempts were made.

The solution
While rapid recovery isn’t a new concept I hadn’t heard of it. I only discovered it while investigating our incident. It turns out Hikari has a brilliant page dedicated to it.
Their advice is two fold:
-
Ensure you don’t cache DNS for too long. The JVM default is indefinite for security reasons, but this didn’t age well with the advent of cloud computing. We changed the default such that any Guardian server with a JVM should only cache DNS for 60s. You can see how Max and Roberto implemented that change for our whole department here.
-
Ensure you set a TCP timeout. Some drivers support it, some don’t. PostgreSQL supports it but sets it to unlimited by default. So by default connections that have been dropped might never be closed.
How to set it?
There’s likely multiple ways to do so, in our specific case I had to add it as a property of the data source. See the pull request here.
What value to set it to?
HikariCP recommends that the driver-level socket timeout be set to (at least) 2-3x the longest running SQL transaction, or 30 seconds, whichever is longer. However, your own recovery time targets should determine the appropriate timeout for your application.
In our case: 30s.

The result
Now that our pool has been reconfigured, let’s test again:
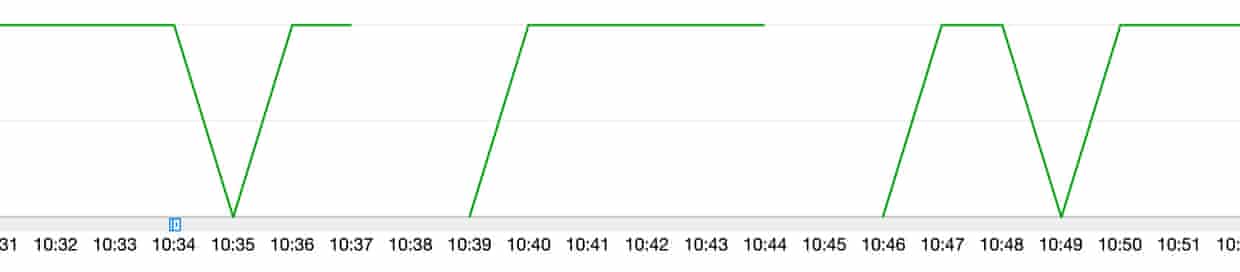
Four fail-overs later, the application always reconnects its 10 connections to the database.
No connections are staying in that zombie state: Success!
Conclusion
Just one line of code or configuration can have a dramatic impact on any production system. In our case, it was really easy to miss. In fact, had I looked for any problem during the review process I wouldn’t have caught the issue - I simply lacked the knowledge to spot it in the first place. This seemingly innocuous settings sits right on the edge between already complex subjects such as TCP, Connection Pools, RDS and DNS.
I hope that by sharing my thoughts and learnings here you might have a second look at how your connection pool is configured. We certainly did and at least one other application was fixed following this work.